-
[MySQL] 풀 텍스트 인덱스(full-text index)를 통한 검색 속도 상승공부/My SQL 2022. 9. 25. 08:28

소개
mysql 에서는 데이터를 검색하기 위해 like '% %'구문이 사용된다. 하지만 like 명령어의 경우 Full Scan 방식이기 때문에 많은 데이터를 검색할때 비효율적이다. 이러한 단점을 극복하고자 Full-text-Index 방식을 도입하고 like 방식과 비교 해보았다.
초기 설정
- MYSQL 5.7이상 버전 사용 (5.7부터 한글 Full-text Index이 도입되었다.)
- InnoDB 또는 MyISAM 테이블
- 컬럼 타입이 CHAR, VARCHAR 또는 TEXT
데이터
-> 정보나루의 서울 도서관에서 소장중인 책 데이터 1800만권을 사용
Full-text Index 이란?
많은 형태의 데이터가 있을때 효율적으로 데이터를 찾는 방법중 하나 이며 텍스트로 구성된 데이터의 내용을 가지고 생성한 인덱스 이다.
데이터를 인덱싱하는 기법
FULL-TEXT 인덱스를 생성 하기 전에 데이터를 인덱싱 하는 두 가지 기법에 배우고 가자
Stop-word parser
→ 공백이나 Tab, 문장 기호, 또는 사용자가 정의한 문자열을 기준으로 토큰을 나누는 기법
ex> 아빠가 방에 들어갔다. → 아빠가 / 방에 / 들어갔다.
N-gram parser
→ n-gram 기법을 사용하여 할당한 토큰의 크기 n만큼씩 데이터를 인덱스로 파싱해두었다가 사용하는 기법
ex> 아빠가 방에 들어갔다. → 아빠 / 빠가 / 방에 / 들어 / 어갔 / 갔다.
FULLTEXT 인덱스 생성
FULL TEXT 인덱스는 테이블을 생성할 때 생성할 수도 있고, 또는 이미 만들어진 테이블에 대해서도 인덱스를 생성할 수 있다. 디폴트는 stop word 파싱이므로 ngram 파싱을 할려면 뒤에 "WITH PARSER ngram" 을 붙여야 한다.
테이블에서 생성
create table "테이블명"( ... "컬럼명"text NOT NULL, FULLTEXT KEY "컬럼명"("컬럼명") ) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;컬럼에서 생성
alter table "테이블명" add FULLTEXT("컬럼명");우리는 이미 만들어진 .ibd 파일을 이용하기 때문에 테이블에서 생성이 불가능 하였다.
그래서 컬럼을 통하여 FULLTEXT 인덱스 생성 하였다.

739초가 걸려 책 제목 컬럼으로 Stop-word 기법의 FULLTEXT 인덱스를 생성 하였다. 
696초가 걸려 책 제목 컬럼으로 N-gram기법의 FULLTEXT 인덱스를 생성 하였다. Stop-word vs N-gram vs like 방식 비교
“개구리”란 단어를 검색시 걸리는 시간과 갯수를 비교 해 보았다.
1. like 경우
select * from library where full_text Like "%개구리%";
18896개의 검색값이 나왔고 0.234초가 걸렸다.
2. Stop-word parser 경우
SELECT * FROM library WHERE MATCH(book_name) AGAINST("개구리");
8766개의 검색값이 나왔고 0.016초가 걸렸다.
3. . N-gram parser 경우
SELECT * FROM library WHERE MATCH(book_name) AGAINST("개구리");
37468개의 검색값이 나왔고 0.109초가 걸렸다.
Stop-word vs N-gram 선택
Stop-word parser의 경우 공백을 구분자로 단어 단위로 저장을 하기 때문에 검색하는 단어가 정확히 일치해야지만 결과를 받을 수 있다. 따라서 N-gram parser 을 선택 하기로 했다.
Stop-word parser는 “빨간개구리” 검색 시 아무 결과가 안나오지만
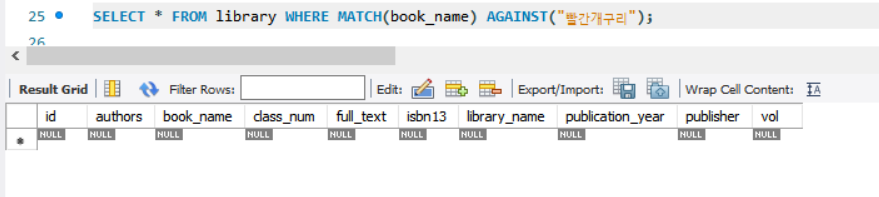
N-gram parser는 “빨간개구리” 검색시 띄어쓰기도 포함된 “빨간 개구리”결과 가 나온다.

FULLTEXT 검색
Full-text Search 검색 쿼리
SELECT * FROM "테이블명" WHERE MATCH("검색할컬럼명"[, ...]) AGAINST('"검색할키워드식" "검색모드");검색 방식
- 자연어 검색(natural search):
검색 문자열을 단어 단위로 분리한 후, 해당 단어 중 하나라도 포함되는 행을 찾는다.

빨간 개구리 검색시 72230개의 데이터가 0.125초안에 출력되었다. - 불린 모드 검색(boolean mode search)
검색 문자열을 단어 단위로 분리한 후, 해당 단어가 포함되는 행을 찾는 규칙을 추가적으로 적용하여 해당 규칙에 매칭되는 행을 찾는다.

- 쿼리 확장 검색(query extension search)
2단계에 걸쳐서 검색을 수행한다. 첫 단계에서는 자연어 검색을 수행한 후, 첫 번째 검색의 결과에 매칭된 행을 기반으로 검색 문자열을 재구성하여 두 번째 검색을 수행한다. 이는 1단계 검색에서 사용한 단어와 연관성이 있는 단어가 1단계 검색에 매칭된 결과에 나타난다는 가정을 전제로 한다.
자연어 검색 vs 불린 모드 검색 비교
자연어 검색 불린 모드 검색 장점 1. 검색속도가 빠르다.
2. 정확도 순에 따라 결과가 정렬1. 구문 검색이 가능하다.
2. 검색의 정확도가 더 높다.단점 1. 관련이 없는 데이터도 리턴 1. 시간이 너무 오래 걸린다. 불린 모드가 검색면에서 더 정확하고 구문 검색을 통해 여러가지 기능을 추가 할 수 있지만 인덱싱 기법을 ngram방식으로 했기에 인덱스가 너무 많아 검색 속도가 낮았다. 그로 인해 어쩔수 없이 자연어 검색을 택하게 되었다.
결론
like 방식 대신 N-gram 인덱싱 기법을 통한 자연어 검색을 택하였다. 그로인해 검색 시간을 1/60정도 단축 시켰고 띄어쓰기 없이도 단어의 검색이 되도록 검색 정확도를 상승 시켰다.
개선할 점
자연어 검색을 택하였기에 띄어쓰기가 안된 검색의 대해서는 불린모드 검색의 비해 정확도가 떨어진다. 해결방법으로는 인덱싱 방식을 형태소분석으로 바꾸어서 하면 검색속도는 유지된 채로 정확도가 상승되리라 생각된다.
참고 레퍼런스
더보기https://dev.mysql.com/doc/refman/5.6/en/fulltext-search.html
https://kmongcom.wordpress.com/2014/03/28/mysql-풀-텍스트fulltext-검색하기/
https://interconnection.tistory.com/95
https://grip.news/archives/1538
https://velog.io/@jduckling_1024/MySQL-FullText-Search
https://gongzza.github.io/database/mysql-fulltext-search/
https://blog.naver.com/PostView.nhn?blogId=jjdo1994&logNo=222348191751